IWC Berlin Hackday milestone 4: fixed CSS issues on this blog. Now all links are correctly colored.
svenknebel.de
IWC Berlin Hackday Intermission: found a bug in Quill while posting about progress. Posting this with curl instead.
IWC Berlin Hackday milestone 3: improved and merged selfauth PRs with Martijn
IWC Berlin Hackday milestone 2: added robots.txt to all domains
IWC Berlin Hackday milestone 1: Fixed Kaja’s autolink functionality
IRC notifications with TikTokBot (on Debian 8)
I was asked about my setup to get notifications for incoming Webmentions in IRC, so here is some documentation for it. I use aaronpk’s TikTokBot project, which provides an HTTP API to IRC and Slack.
prerequisites
You need a (private) IRC channel somewhere. I personally run my own IRC server using Oragono. It’s on the same server as my IRC bouncer, so I do not have to expose it to the Internet (side-note: if someone has documentation about how to set up a secured, private IRC server with strict user authentication against some backend, I’d love to hear about it). You could also use a private channel on a public network though.
You also need a server to run TikTokBot itself, which requires ruby (here, the same VPS running Debian 8 that runs all my stuff).
primer on running Ruby programs
(I’m not a Ruby dev, corrections welcome)
Ruby dependencies are organized in "Gems". A project’s Gemfile lists all dependencies of the project. A Gemfile.lock is generated to freeze exact versions of the dependencies. Bundler is a tool to create an isolated environment for a project, and then to run applications in this environment (instead of installing dependencies globally, they end up in a .vendor subdirectory)
install TikTokBot
First, install ruby and bundler:
$ apt install ruby bundlerCreate a directory for TikTokBot, and download it there. I cloned the git repo, but of course you can also download the zip file from Github and upload it’s contents.
# git clone https://github.com/aaronpk/TikTokBot.gitcheck your ruby version
# ruby -vif it is below 2.2.2, the dependency version snapshot in the current Gemfile.lock doesn’t work. As a workaround, I just deleted it, and let the installation pick it’s own versions, and it works out OK for now.
install dependencies:
# bundle installconfigure TikTokBot
TikTokBot has 3 configuration files.
In config.yml a server needs to be defined, and to bot is instructed to join a channel (e.g. #webmentions) – look at the example file for reference. Similarly, in token.yml at least a global token has to be created – all other lines can be deleted. We don’t need any hooks (=webhooks sent when specific things are said in IRC), so hooks.yml is filled with
hooks: []start TikTokBot
as described in the README, run
# bundle exec ruby tiktok.rb localirc(replace localirc with the name of your server definition)
Now the bot should connect to IRC and appear in the channel.
test sending
Now we’ll send the bot a command to send a message to the channel. This is done by sending a form-encoded POST request to the /messag endpoint of it’s API, e.g. using curl:
# curl -H "Authorization: Bearer TOKEN" -X POST -F 'channel=#webmentions' -F 'content=HELLO WORLD!' http://localhost:9000/message(obviously, fill in your actual token, the channel and the API location)
persistent start using systemd
I’ve written a systemd unit file for TikTokBot, which runs it as it’s own user and group (which have to be created before):
[Unit]
Description=Tiktokbot for local IRC
[Service]
ExecStart=/usr/local/bin/bundle exec ruby tiktok.rb localirc
WorkingDirectory=/srv/bots/tiktokbot
User=tiktokbot
Group=tiktokbot
[Install]
WantedBy=multi-user.targetPlace it in /etc/systemd/system/ as e.g. tiktok_local.service and systemctl enable and systemctl start it.
integrate with the rest of your site
Now, you can start sending form-encoded POST requests just as above to TikTokBot and it’ll report events in IRC.
note on restarts
During testing it has occasionally happened to me that the API portion of TikTokBot didn’t shut down cleanly, which meant that starting TikTokBot again failed with an error like
* Listening on tcp://127.0.0.1:9030
== Someone is already performing on port 9030!In this case, you have to manually kill the left-over puma processes. If you find a solution to this problem, please contribute it at this GitHub issue
On one hand: hackable == insecure == bad. On the other hand: hackable == open to "improvement". Cheap hardware with good microphones anyone?
Also, I did not know that the Echo has a hardwired microphone-mute button.
Listening to the #refresh session at #IndieWebSummit my brain constantly gets confused by the mention of "Gentoo" people in onboarding talk
Notes for HomebrewWebsiteClub 2017-04-05
We started by discussing future plans for our meetup, especially how to promote it and how to find a better location. (Afterwards, Florian created a group at meetup.com) I've also been building a web site for HWC – mostly for learning CSS Flexbox and Grid layouts, but maybe we’ll turn it into an actual page.
Florian had brought a bunch of interesting links:
- ethicalweb.org
- fairwebservices.org
- ind.ie/ethical-design
- criticalengineering.org
- The Social Design of Technical Systems: Building technologies for communities
This led back to a discussion from 2 weeks before, where we had talked about about tracking and respecting user requests like the Do-Not-Track-header. Joel mentioned the CommonTerms project, which proposes icons for typical clauses in Terms and Conditions.
He showed how on one of his web pages, he does not just disable tracking for users that have the Do Not Track header set, it also clearly indicates this to users:
“Active tracking using Piwik on this page has been disabled based on your browser's Do Not Track (DNT) setting.”
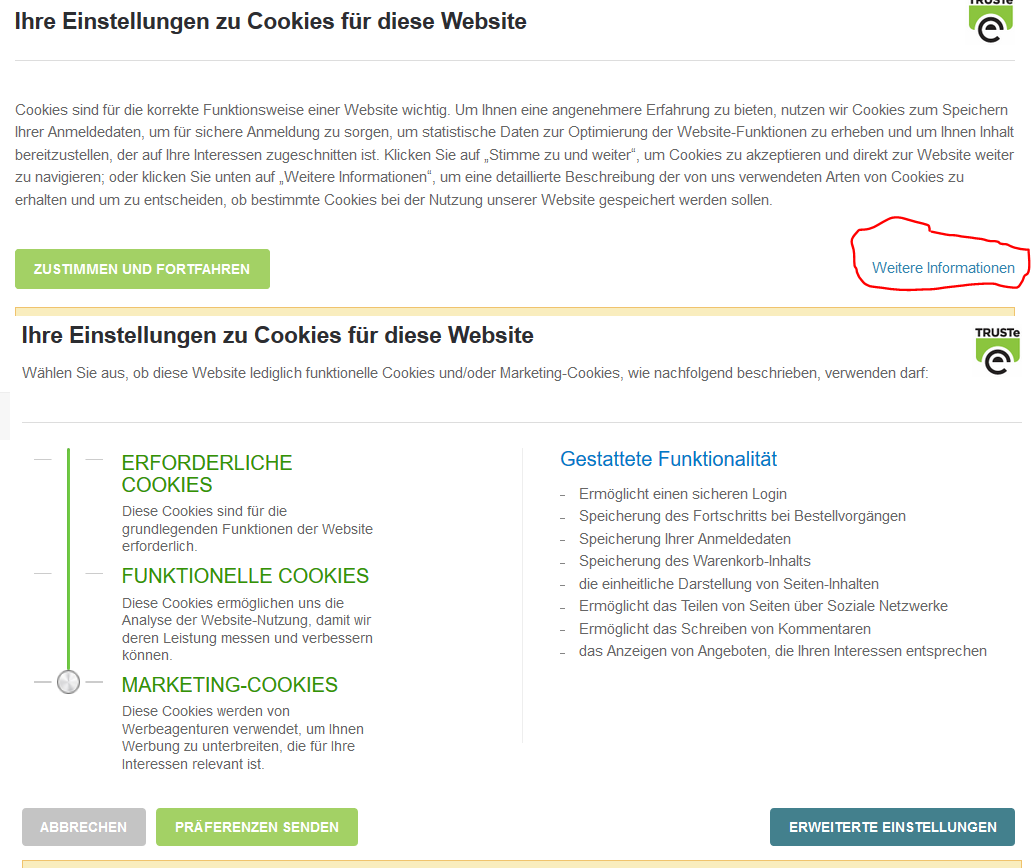
Another example are the cookie banners made by TRUSTe, which allow a visitor to choose between different types of cookies used, if they find the right link to click:
Differential privacy was mentioned, but nobody knew enough to really talk about it. Here is a slide deck about the topic a friend made a few years ago.
Another privacy aspect covered was how federated/distributed systems by design create many additional copies of data, with less centralized control over them. This is of course a desired property, but it also means that these copies might be hard to delete and are presented in different aggregations users might not be aware of. While a deleted silo post is expected to be gone from outside of dedicated archives, a deleted post on a GNU Social/Mastodon instance likely is still visible on other federated instances. If one instance blocks search engines using robots.txt, content from it still might be indexed on other sites. In an IndieWeb context, a site that backfeeds from Twitter likely still shows deleted interactions (and in general shows them in an unexpected context). Many IndieWeb tools also have public logs or APIs retaining data, which might be surprising to users. (e.g. brid.gy, webmention.io)
Other random links that were mentioned:
- Meddelare by Joel, for showing aggregate counts of silo interactions, proxied through a private server.
- some notes on privacy settings for Wordpress installations
Talking about our private sites, only I had progress to present: I improved my Micropub endpoint, and I have now explicit headers for replies, bookmarks, …: example post